
شوق یادگیری و راه اندازی کسب و کار دیجیتال دارید؟ تشنه آموزش و اجرای سریع ایدههایتان هستید؟ همین حالا تماس بگیرید.




در فضای توسعهٔ نرمافزار و برنامهنویسی، دو مدل عمده بهلحاظ نوع عملیات سیستم وجود دارد: مدل sync و async.
در فضای async، منظور تبادل داده یا عملیات بهصورت ناهمزمان میباشد؛ بهعبارت دیگر، یک سیستم میتواند کار خود را انجام دهد و بخشهایی از کار خود را با تأخیر یا با زمانبندی متفاوت به اتمام برساند.
بهعنوان مثال، یک سیستم فروشگاهی میتواند در لحظه پرداخت شما را نهایی سازد، با اینحال پیامک مربوط به فاکتور سفارش شما را با تأخیر یا در فاصلهٔ زمانی نسبت به خرید ارسال کند. به این مدل فرایند نرمافزاری، فرایند async گفته میشود و در فضای تولید و توسعهٔ نرمافزار، کاربرد وسیعی دارد.
یکی از ابزارهای فرایندهای async، بروکرها (broker) و صفها (queue) میباشند. در فضای توسعهٔ نرمافزار، حجم گستردهای از بروکرها تعریف شده و هرکدام برای کاربرد خاصی بهینه شدهاند.
در این پست، در ابتدا به بررسی انواع بروکرها خواهیم پرداخت و سپس به بررسی دقیقتر آخرین قابلیتهای کافکا (Apache Kafka) و کاربردهای آن در فضای میکروسرویس خواهیم پرداخت.

پوستر این پست اشاره به کتاب «کافکا در کرانه» (Kafka on the Shore) رمانی است از هاروکی موراکامی، نویسنده مشهور ژاپنی، که نخستین بار در سال ۲۰۰۲ منتشر شد و خیلی زود به یکی از محبوبترین آثار او تبدیل شد. این رمان از جنس رئالیسم جادویی و سورئال است و مضامین فلسفی، اسطورهای و روانشناختی را در دل یک داستان معمایی روایت میکند. یکی از مشهورترین و پر استفاده ترین بروکرهای حال و حاضر دنیا، کافکا می باشد.
در دنیای مدرن توسعه فرآیندهای نرم افزاری، چند سناریو، ضرورت استفاده از بروکرها را مشخص می کند:
الف) در حجم خیلی بالای تراکنش هستیم و محدودیتهای منابع سبب میشود که قادر نباشیم تمام درخواستها را در لحظهٔ ایجاد پاسخ دهیم. از بروکرهای مبتنی بر queue یا صف استفاده میکنیم تا همهٔ درخواستها را دریافت کرده و سپس به نوبت به آنها پاسخ دهیم. مثال عملی این موضوع میتواند طراحی یک شبکهٔ اجتماعی مثل توییتر (یا ایکس فعلی) باشد که در یک لحظه بعد از یک توییت از یک سلبریتی، حجم نامتعارف و غیرمعمولی از بازدیدها روانهٔ آن میشود. اگر توییتر تمام درخواستها را دریافت نکند و افراد را در صف قرار ندهد، احتمال دارد هم سلبریتی مذکور دیگر از آن استفاده نکند، و هم مخاطبانِ خودِ توییتر که امکان استفاده نداشتند، کمتر به سراغ آن بروند.
ب) در سیستمهای پیادهسازیشده توسط چند زبان برنامهنویسی، برای تبادل داده بهصورت async، هیچ مکانیزمی به قدرتِ بروکرها تا امروز شناسایی و ارائه نشده است.
پ) در زمانهایی که منابع مختلف اقدام به ارسال داده میکنند. فرض بفرمایید که چند میلیون دستگاه IoT در حال ارسال داده به سرور شما هستند؛ همزمان کاربران در حال استفاده از اپلیکیشن موبایلِ متصل به همان نرمافزار هستند، و بخش دیگری از کاربران در حال نهاییسازی سفارش خود در پنل وبسایت شما.
در فضای توسعه نرم افزارهای مبتنی بر معماری میکروسرویس که در آن ها حضور داشتم بروکروهای مورد استفاده به شرح زیر بودند
|
نوع بروکر |
شرکت |
|---|---|
|
Beanstalkd, Rabbitmq |
فیدیبو |
|
Rabbitmq |
دیجی پلاس |
|
Rabbitmq, Kafka |
شیپور |
|
Redis (queue), Kafka |
ازکی |
|
Rabbitmq |
مدیاپردازش |
|
Kafka |
دال / مانیسا (انتخاب) |
همان طور که مشاهده می کنید، در حدود 10 سال از سابقه ای که داشتم، از بروکرهای مختلف به فراخور شرایط و تکنولوژی هر پروژه استفاده کردم. مهم ترین وجه تمایز این بروکرها حجم و مقیاس استفاده از آن ها است.
زمانی که با نرخ بالایی از داده ها برای جابه جایی توسط بروکر روبرو هستیم، استفاده از kafka توصیه می شود. اما اگر مقیاس محدودتر است و نیازی به کلاستر نیست، بی تردید RabbitMq انتخاب مناسب تری می باشد.
سازگاری زبان های برنامه نویسی با این بروکرها می تواند از پارامترهای دیگر تعیین انتخاب نوع آن باشد، به عنوان مثال kafka با زبان java سازگاری بالایی دارد و خود آن نیز بر اساس جاوا تهیه شده است
موضوع دیگر در انتخاب بین بروکرها قابلیت های ارائه شده در هریک می باشد
Kafka:
یک پلتفرم event streaming و مبتنی بر log است.
دادهها بهصورت توالی (append-only) روی دیسک ذخیره میشوند و قابلیت پردازش real-time و batch را همزمان دارد.
RabbitMQ:
یک message broker کلاسیک مبتنی بر صفها (queue) و push-based است.
بیشتر برای مسیردهی و مدیریت پیام بین سرویسها بهکار میرود.
Kafka:
مصرفکنندهها (consumers) خودشان داده را pull میکنند.
پیامها در log نگه داشته میشوند و چندین گروه مصرفکننده میتوانند بهطور مستقل آنها را بخوانند.
RabbitMQ:
پیامها را بهصورت push به مصرفکنندهها ارسال میکند.
پس از تحویل، پیام از صف حذف میشود (مگر اینکه با ack مدیریت شود).
Kafka:
توان عملیاتی بسیار بالا (میلیونها پیام در ثانیه).
مناسب برای big data، تحلیل رویدادها و سناریوهایی با جریان عظیم داده.
RabbitMQ:
کارایی متوسط تا بالا، اما برای بارهای خیلی سنگین بهاندازهٔ Kafka مقیاسپذیر نیست.
مناسب برای سیستمهای عملیاتی روزمره با حجم پیام کمتر.
Kafka:
پیامها روی دیسک و بهصورت توزیعشده ذخیره میشوند.
قابلیت نگهداری طولانیمدت دادهها (حتی ماهها و سالها).
RabbitMQ:
پیامها بهطور پیشفرض کوتاهمدت در صف نگهداری میشوند.
برای نگهداری بلندمدت طراحی نشده است.
Kafka:
At most once، at least once، و exactly once (با پیکربندی مناسب).
بیشتر تمرکز روی پردازش دقیق دادهها در مقیاس بالا.
RabbitMQ:
پشتیبانی قوی از ack، retry و dead-letter queues.
بیشتر برای تضمین تحویل پیامهای حیاتی در سیستمهای تراکنشی استفاده میشود.
Kafka:
Pub/Sub واقعی با قابلیت داشتن چند گروه مصرفکننده.
بهترین انتخاب برای event sourcing و stream processing.
RabbitMQ:
پشتیبانی قوی از routing، fanout، direct exchange و topic exchange.
انعطافپذیری بالاتر در مسیردهی پیچیدهٔ پیامها.
Kafka:
جمعآوری لاگها، مانیتورینگ real-time، پردازش دادههای حجیم، تحلیل داده (big data analytics).
معماریهای میکروسرویسی مبتنی بر event-driven.
RabbitMQ:
صفبندی وظایف (task queue)، ارسال اعلانها، مدیریت درخواستهای سرویسبهسرویس (service-to-service).
سیستمهای بانکی و پرداخت، که نیازمند تضمین تحویل دقیق پیام هستند.
زمانی که حجم داده های بالا می رود، دیگر یک بروکر تنها پاسخگو نیست و بهسرعت دچار گلوگاه (bottleneck) یا نقطهٔ خطای منفرد (Single Point of Failure) میشود. کلاستر بروکر به مجموعهای از چند بروکر گفته میشود که بهصورت هماهنگ کار میکنند و بهعنوان یک سیستم یکپارچه دیده میشوند. در این حالت:
دادهها بین چند بروکر توزیع میشود.
وظایف بین بروکرها load balance میگردد.
خطا یا ازکارافتادن یک بروکر، باعث توقف کل سیستم نمیشود (Fault Tolerance).
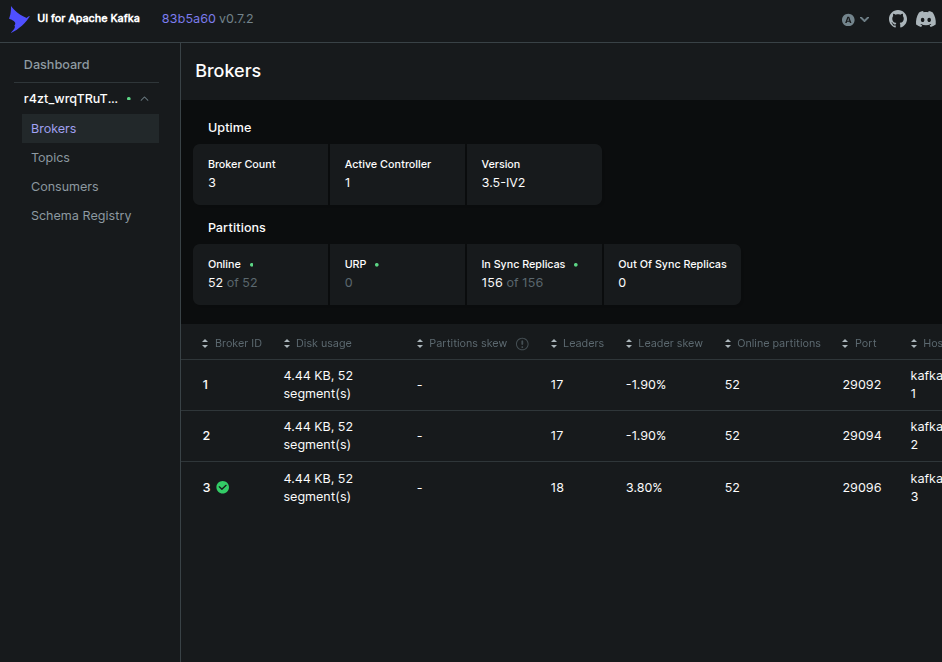
در تصویر فوق یک کلاستر سه node کافکا را مشاهده می کنید که node شماره 3 به عنوان سرپرست یا پاسخ دهنده اصلی انتخاب شده است. لازم به توضیح است که این انتخاب سرپرست در هر لحظه می تواند متفاوت باشد و به فراخور شرایط سیستم، به صورت خودکار تعویض می شود
لینک نمونه به منظور ایجاد یک کلاستر سه node در docker در آدرس زیر موجود است:
https://github.com/shayand/kafka-cluster-kraft.git
در کافکا برای هر دسته بندی خدمات topic تعریف می شود و هر topic مشخصه های خاص مربوط به خود را می تواند داشته باشد
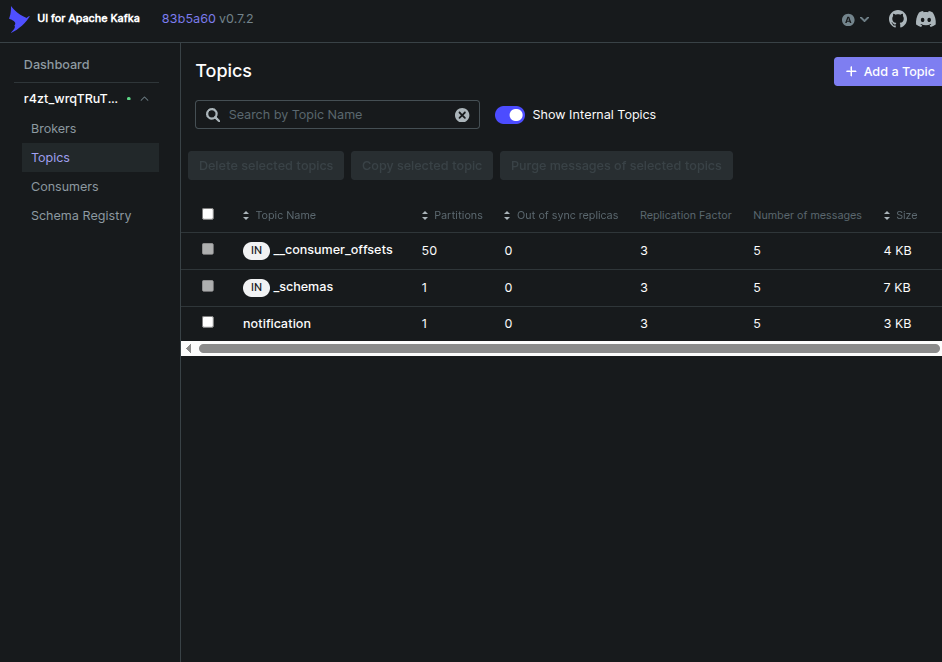
در واقع topic ها فصل مشترک و محل تلاقی ورود داده ها و استفاده از آن ها هستند. سرویس هایی که از داده ها استفاده می کنند با عنوان consumer شناخته می شوند و در تصویر زیر مشخص هستند
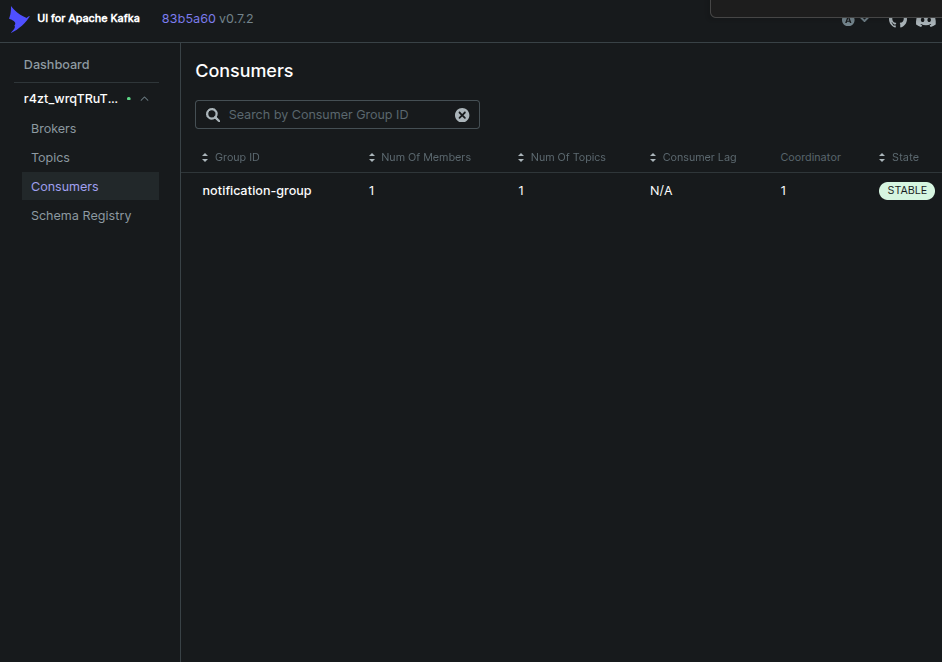
در نسخ پیشین مدیریت خوشه یا کلاستر با سرویسی به نام zookeeper بود که در نسخ جدید این امکان وجود دارد که از مدیریت جدید کلاستر با عنوان kraft استفاده شود
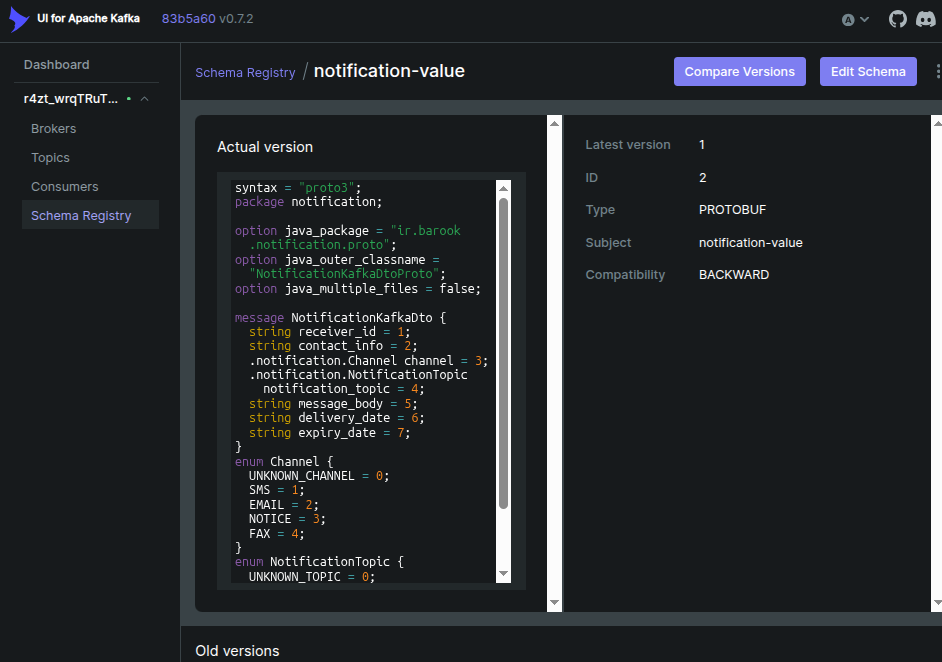
تصور کنید که بین تعداد بالای سرویس، انواع محتلف پروتوکل داده ای، در حال رد و بدل است، به عنوان مثال json و protobuffer و هر کدام از این پروتوکل ها دارای تغییراتی خواهند بود در طول زمان. کافکا در جدیدترین راهکار ارائه داده شده برای این موضوع از schema registry رو نمایی کرده است
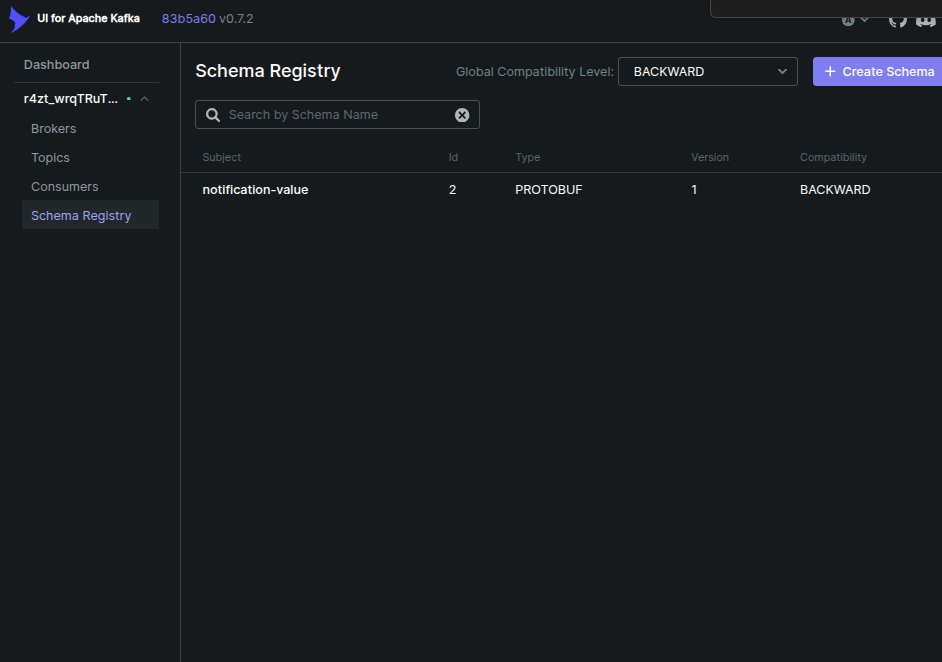
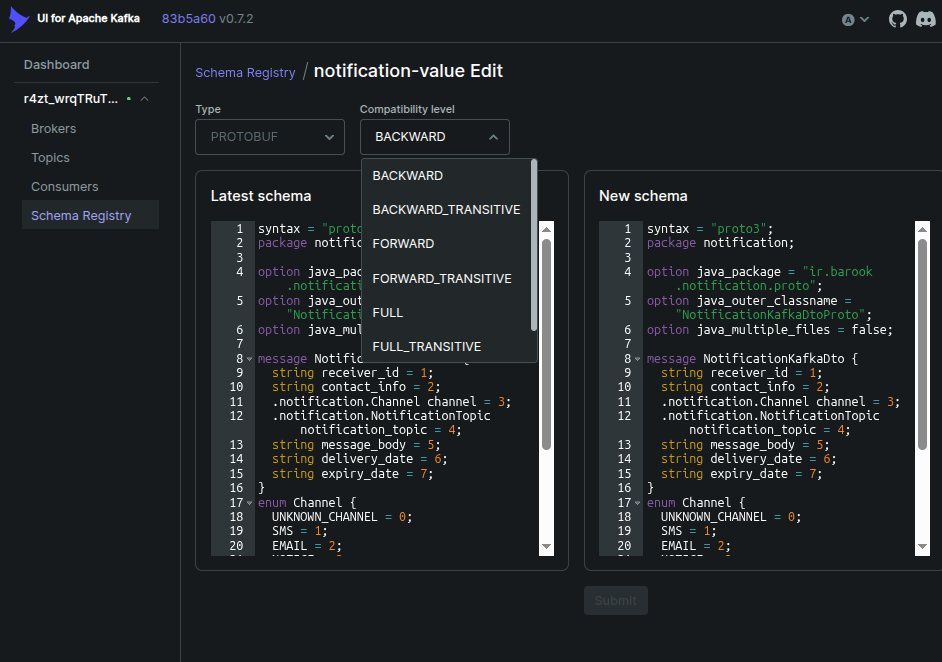
شما در schema registry قادر هستید تا انواع مختلف داده ها با پروتوکل های متفاوت را ثبت کرده و تغییرات نسخ آن را داشته باشید. علاوه بر این در فریم ورک های مختلف schema registry قابل ثبت است و می توانید برای تبدیل داده به فرمت مورد نیاز کافکا و هم چنین تبدیل داده به فرمت قابل پذیرش در لایه اپلیکیشن از آن استفاده کنید. دیگر نیاز به تهیه serializer و یا unmarshaller نیستید و همه این تبدیل ها توسط خود schema regsitry صورت می پذیرد
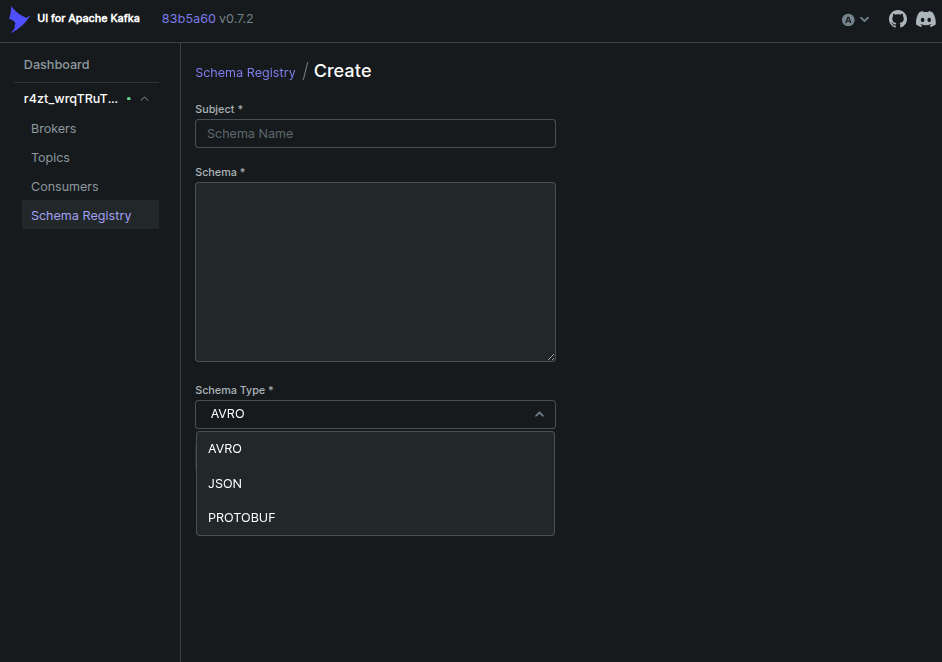
shema registry انواع شماهای AVRO , JSON, PROTOBUF را پشتیبانی می کند. علاوه بر این امکان تغییر نسخ قرارداد و سازگارسازی کلیه پروژه ها بر مبنای آن را خواهید داشت
Protobuf:
یک فرمت باینری (binary) است.
دادهها بهشکل فشرده و با schema مشخص (فایل .proto) تعریف میشوند.
انواع دادهٔ دقیق (int32, int64, float, double, enum, …) دارد.
JSON:
یک فرمت متنی (text-based) و انسانخوان است.
نیازی به schema ندارد و دادهها با جفت کلید–مقدار ذخیره میشوند.
انواع داده سادهتر (string, number, boolean, array, object).
Protobuf:
بسیار کمحجمتر از JSON (حدود ۳ تا ۱۰ برابر کوچکتر).
پردازش سریعتر چون باینری و strongly typed است.
JSON:
حجیمتر (بهدلیل وجود کلیدها بهصورت متنی).
سرعت پردازش کمتر در مقیاس بزرگ.
Protobuf:
برای انسان قابلخواندن نیست (باینری).
نیازمند ابزار یا deserializer برای مشاهدهٔ دادهها.
JSON:
کاملاً انسانخوان و قابلفهم حتی بدون ابزار خاص.
برای دیباگ و تست دستی مناسبتر.
Protobuf:
با schema evolution پشتیبانی میشود (میتوان فیلد جدید اضافه کرد بدون شکستن سازگاری).
نیاز به فایل .proto برای تولید کد در زبانهای مختلف دارد.
JSON:
بسیار انعطافپذیر، میتوان دادهٔ جدید اضافه کرد بدون نیاز به تعریف قبلی.
ولی بهدلیل نداشتن schema، اعتبارسنجی (validation) سختتر است.
Protobuf:
توسط گوگل توسعه داده شده و برای اکثر زبانهای برنامهنویسی (Java, C++, Go, Python, Kotlin, …) ابزار رسمی یا جانبی دارد.
JSON:
تقریباً همهٔ زبانها بهطور پیشفرض پشتیبانی میکنند (parserها و serializerهای آماده).
Protobuf:
سیستمهای توزیعشده با حجم بالای داده.
ارتباط سرویسبهسرویس (microservices) خصوصا ارتباط Backend با Backend.
شبکههایی با محدودیت پهنای باند.
JSON:
APIهای عمومی و RESTful.
تبادل داده در جاهایی که خوانایی انسانی اهمیت دارد.
نمونهسازی سریع (rapid prototyping).
نمونه schema ساخته شده protobuf:
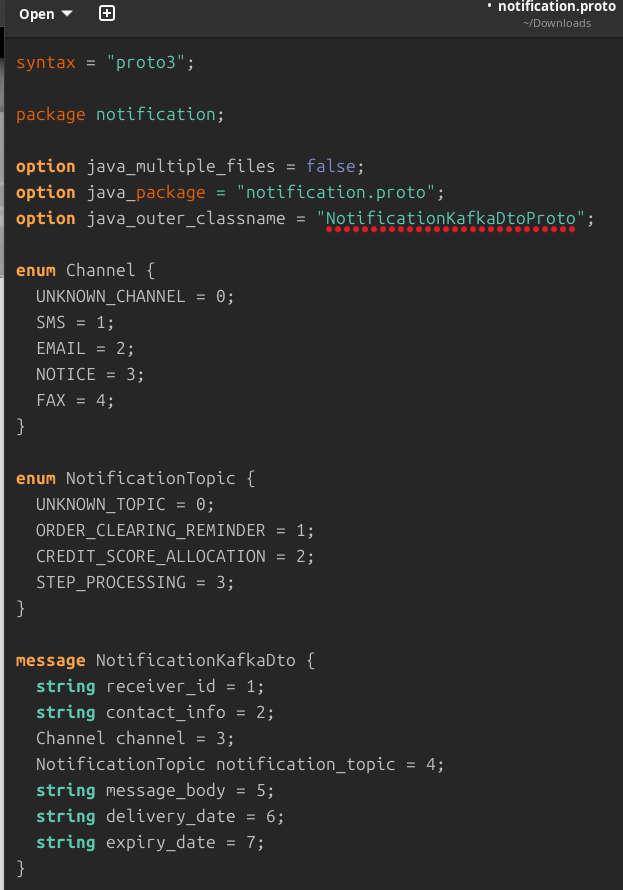
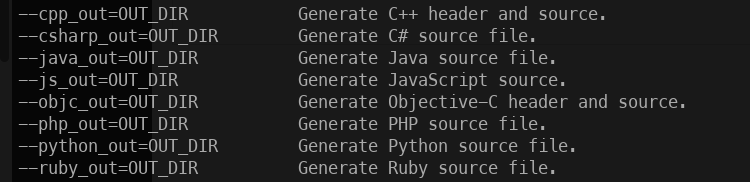
دستور تبدیل فایل های .proto به متودهای مورد استفاده در هر زبان برنامه نویسی:


سپیدان نامی است، یادآور رنگ سپید مظهر پاکی و همین طور شهری است برف خیز، از توابع استان فارس که در اکثر اوقات سال پوشیده از برف میباشد و از این جهت واسطه خیر و برکت به سایر شهرها نیز میباشد.


دیدگاهها
پیوند ثابت
پیوند ثابت
پیوند ثابت
پیوند ثابتافزودن دیدگاه جدید